Reflections on AI at the end of 2025
▼* For years, despite functional evidence and scientific hints accumulating, certain AI researchers continued to claim LLMs were stochastic parrots: probabilistic machines that would: 1. NOT have any representation about the meaning of the prompt. 2. NOT have any representation about what they were going to say. In 2025 finally almost everybody stopped saying so. * Chain of thought is now a fundamental way to improve LLM output. But, what is CoT? Why it improves output? I believe it is two things: 1. Sampling in the model representations (that is, a form of internal search). After information and concepts relevant to the prompt topic is in the context window, the model can better reply. 2. But if you mix this to reinforcement learning, the model also learns to put one token after the other (each token will change the model state) in order to converge to some useful reply.
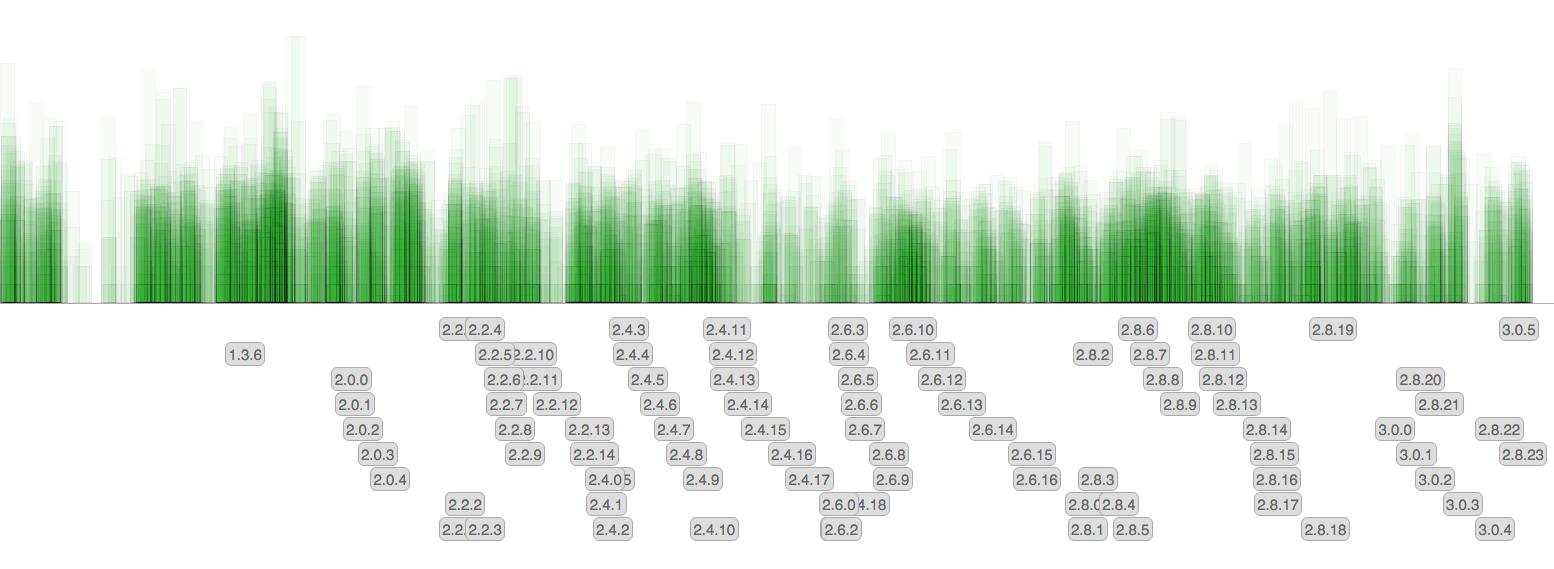 Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.
Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.