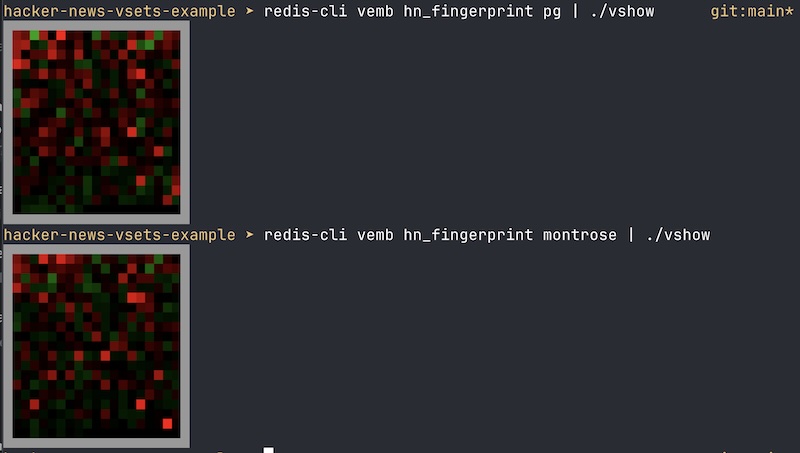
About three years ago I saw a quite curious and interesting post on Hacker News. A student, Christopher Tarry, was able to use cosine similarity against a vector of top words frequencies in comments, in order to detect similar HN accounts — and, sometimes, even accounts actually controlled by the same user, that is, fake accounts used to uncover the identity of the writer. This is the original post: https://news.ycombinator.com/item?id=33755016 I was not aware, back then, of Burrows-Delta method for style detection: it seemed kinda magical that you just needed to normalize a frequency vector of top words to reach such quite remarkable results. I read a few wikipedia pages and took mental note of it. Then, as I was working with Vectors for Redis I remembered about this post, searched the web only to discover that the original page was gone and that the author, in the original post and website, didn’t really explained very well how the data was processed, the top words extracted (and, especially, how many were used) and so forth. I thought I could reproduce the work with Vector Sets, once I was done with the main work. Now the new data type is in the release candidate, and I found some time to work on the problem. This is a report of what I did, but before to continue, the mandatory demo site: you can play with it at the following link: https://antirez.com/hnstyle?username=pg&threshold=20&action=search NOTE: since the dataset takes 700MB of RAM, in my tiny server, in the next months I may take this down. However, later in this post you will find the link and the Github repository with the code to reproduce everything from scratch. NOTE2: I hope the web site will survive, it's a very crude Python script. I benchmarked the VSIM command in such a small server and yet it can deliver 80k VSIM per second! The wonders of int8 quantization, together with a few more optimizations. But the Python script is terrible, creates a new Redis connection each time and so forth. Fingers crossed. # Raw data download and processing Well, the first problem I had, in order to do something like that, was to find an archive with Hacker News comments. Luckily there was one with apparently everything posted on HN from the start to 2023, for a huge 10GB of total data. You can find it here: https://huggingface.co/datasets/OpenPipe/hacker-news and, honestly, I’m not really sure how this was obtained, if using scarping or if HN makes this data public in some way. Since I’m not a big fan of binary files, in the specific case of public datasets at least, I used two Python scripts in order to convert the Parquet files into something smaller and simpler to handle. The first script, gen-top-words.py, takes the binary files and generates a txt file with the list of the top N words used in the dataset. It generates 10k words by default, but for the statistical analysis a lot less are needed (or, actually: if you use too many words you no longer capture the style, but the kind of content a user is talking about!). Then, another Python script, accumulates all the comments for each single user and generates a very big JSONL file where there are just two keys: the user name and the frequency table of all the words used by a given user in all the history from HN starts to 2023. Each entry is like that: {"by": "rtghrhtr", "freqtab": {"everyone": 1, "hates": 1, "nvidia": 1, "but": 1, "treats": 1, "ati": 1, "as": 1, "an": 1, "afterthought": 1, "another": 1, "completely": 1, "useless": 1, "tool": 1, "to": 1, "throw": 1, "on": 1, "the": 1, "pile": 1}} At this point, the final script, insert.py, could do all the real work: to apply the Borrows method for each user, create the user style vector, and insert it into Redis. The advantage of pre-processing the files (a slow operation) is that the insertion script could be called more easily with different parameters (especially the number of top words to use) in order to see the different results more promptly, without the need to re-process the Parquet files each time. # How the Burrow method works? In the original post, Christopher wrote that you just need to normalize the frequency of the words usage and apply cosine similarity. Actually the process is a bit more involved. First, let’s ask ourselves, how this method actually works, in its essence? Well, it wants to capture words that each specific user over-uses or under-uses compared to the expected “average” language. To do so, we actually use the following steps (from the Python code). That’s what we do for each of the top words: # Convert to relative frequency rel_freq = frequency / total_words # Standardize using z-score: z = (freq - mean) / stddev mean = word_means.get(word, 0.0) stddev = word_stddevs.get(word, 1.0) # Default to 1.0 to avoid division by zero z_score = (rel_freq - mean) / stddev # Set the z-score directly in the vector at the word's index vector[word_to_index[word]] = z_score So we start by “centering” the frequency the user used a given word, by subtracting the *global* usage frequency for that word. This way, we have a number that describes how much the user under (negative) or over (positive) used such word. But, if you think at it, words that have a much higher variance among usage of different writers are less important, when they change. We want to amplify the signal of words that are under of over used by this user in a much greater way compared to the normal variance of the word. This is why we divide the centered frequency by the global standard deviation of the word. Now we have what is called the “z score”, an adjusted measure of how much a given word is an outlier in one or the other direction. Now, we are ready to insert the word into a Redis vector set, with just: VADD key FP32 [blob with 350 floats] username (I’ll not cover the details of vector sets here since you can find the doc here -> https://github.com/redis/redis/blob/unstable/modules/vector-sets/README.md) Note that Redis performs L2 normalization of the inserted vectors, but remembers the L2 value in order to return back the values when VEMB is used to retrieve the associated vector, so the z_score was set as it is. Finally, with VSIM, we can get similar users: 127.0.0.1:6379> vsim hn_fingerprint ele pg 1) "pg" 2) "karaterobot" 3) "Natsu" 4) "mattmaroon" 5) "chc" 6) "montrose" 7) "jfengel" 8) "emodendroket" 9) "vintermann" 10) "c3534l" All the code (but the webapp itself) can be found here: https://github.com/antirez/hnstyle The README file explains how to reproduce every part. # Why 350 words? One of the things missing in the original post that stimulated this blog post, is how many top words one should use. If you use too many words, you’ll see many comments of mine about Redis, since Redis is one of the top 10k words used. Guess what? I did exactly this error, initially, and VSIM continued to report users that talked about similar topics than myself, not with similar *style*. But fortunately the Internet Archive cached the Christopher results for the “pg” account, here: https://web.archive.org/web/20221126235433/https://stylometry.net/user?username=pg So now I could tune my top-k words to get similar results. Also, reading the original papers, I discovered that, with my surprise, for the analysis to work well you need even as little as 150 words. And in general the range from 150 to 500 is considered to be optimal. Warning: don’t believe that when you search for a user you’ll find mostly fake accounts. For many fake accounts there is too little data, as often people create throw away accounts, write a few comments, and that’s it. So most of the accounts associated with a given user style will be just other people that have a similar writing style. This method I believe is quite powerful in distinguishing who is a native speaker and who is not. This is especially clear from the vectors visualization below. # Validate and visualize… Another thing that I reproduced (also an idea from OP) was to try inserting the same users in two variants, like antirez_A and antirez_B, using two different set of comments. Then check if asking for similar users to antirez_A would report B. Indeed, for *most* of the users I tested this against, it worked very well, and often times it was the top result. So we know that actually our method works. But since from the vectors it is so easy to “see” a style, what about our naked eyes? Recently I switched to Ghostty as my terminal, and it supports the Kitty graphics protocol, so you can display bitmaps directly in the terminal window. It is quite some time I want to play with it. Finally I had a good reason to test this feature.What’s happening above is that we call the VEMB command, that returns just a list of floats (the vector). Then the vshow utility, also part of the repository, will care to find the smallest square that can contain the vector and show positive values in red, negative in green. As you can see, as a non native speaker I over-use very simple words and under-use more sophisticated words. Other authors stress certain specific words, others are much more “plain”, showing less artifacts. At some point I was curious about what was really happening there: what words I would use too much and too little? So in the demo website you can also press the button to analyze a given user, and see the top 10 words over-used and under-used. Well, a few of mine are definitely due to my issues with English grammar :D Ok, enough with this investigation! Vector sets are now in Redis 8 RC1 and I have more work to do, but this was fun, and I believe it shows that vectors were definitely cool even before AI. Thanks for reading such a long post. EDIT: I forgot to say that the insert.py script also inserts the JSON metadata with the total words written by the user. So you can use FILTER in order to only show matches with a given number of words. This can be useful to detect duplicated accounts since often they are used only seldom, when the identity must be covered: 127.0.0.1:6379> vsim hn_fingerprint ele pg FILTER ".wordcount < 10000" 1) "montrose" 2) "kar5pt" 3) "ryusage" 4) "corwinstephen" 5) "ElfinTrousers" 6) "beaned" 7) "MichaelDickens" 8) "bananaface" 9) "area51org" 10) "william42" EDIT2: In case the matches look suspicious to you (meaningless), like tptacek noted in a comment in the HN submission of this blog post, here is a "visual" match that shows how, for instance, montrose and pg are really similar in the words usage patterns: