Being Linux Torvalds
▼(This blog post was adapted from the transcription obtained from my YouTube video at https://www.youtube.com/watch?v=l6lxgYeVZqs) When Linus Torvalds developed the first Linux kernel, he had studied the Minix sources, he had studied computer architecture, he had the base knowledge needed, and he was obviously a very brilliant programmer. But that operation of writing a minimal yet working Unix kernel for the 386 (at the beginning Linux was, let's say, mono-architecture) was something within the reach of many other programmers and students. Many in the sense of, I don't know, 0.1%, one in a thousand, one in ten thousand. Obviously most people are not able to do this kind of feat, but a lot of people are. If you look at Hacker News in the latest years, you'll see how many projects of kernels written in C, microkernels implemented from scratch, kernels written in Rust, kernels made in all sauces and manners, small Unix systems created vertically for the Raspberry Pi, operating systems for the ESP32 and so forth. Writing a kernel is not something within everybody's reach, but it is something that many can complete, if they put enough effort into it. Then, of course, not everybody will do it well. He is a genius programmer, without any doubt, so he did it better.
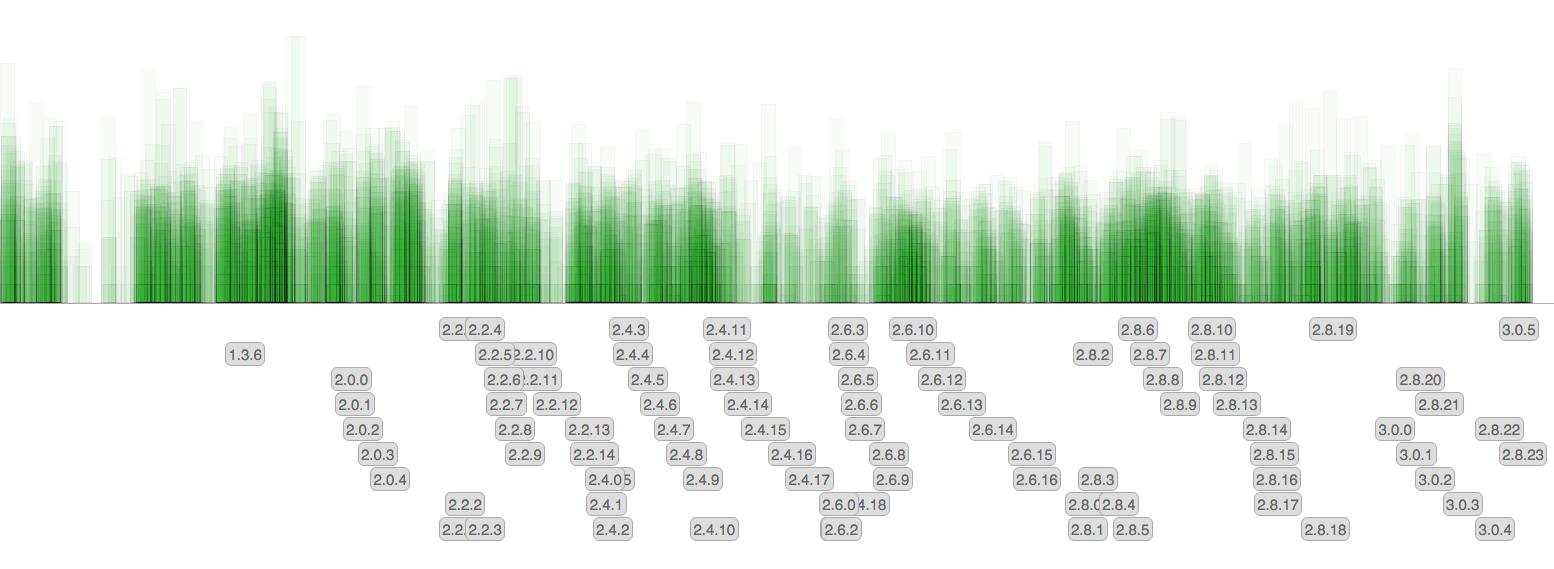 Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.
Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.